그래프로 코드를 읽다 — 당신의 코드가 별자리가 되는 순간
AI는 코드를 잘 쓴다. 그러나 어디에 무엇이 있는지를 찾아주는 것은 여전히 사람의 일이다. CodeScan은 그 일을 작은 단일 바이너리에게 넘긴다.
이 글은 블룸AI 스튜디오가 오픈한 코드 인덱서 BlumnAI-Studio/CodeScan을 소개한다. 대상은 여러 저장소와 대형 레거시 코드를 AI 도구와 함께 다루는 개발자 — 즉 클로드 코드, 코덱스, 또는 자체 에이전트에 코드 컨텍스트를 매번 새로 쥐어주느라 컨텍스트 윈도우가 폭발하는 사람들이다.
1. 왜 또 하나의 코드 분석기를 만들었나

1.1 AI가 코드를 짜는 시대, 우리의 로컬은 점점 무거워졌다
레거시 코드 개선, 신규 모듈 개발, 다른 저장소의 좋은 개념을 영입하는 작업 — 모두 AI 덕분에 가속화되었다. 가속의 부작용은 단순하다. 나의 로컬에 관리해야 할 저장소가 늘어났다. 서비스 운영 코드 한 벌, 그것을 개선하는 보조 저장소 한 벌, 영입을 검토 중인 오픈소스 두세 벌. 한 사람의 워킹 디렉터리가 작은 모노레포가 되어 간다.
초기에는 클로드 코드 세션을 열고 Grep ALL 한 번이면 충분했다. 코드량이 적을 때, 그리고 저장소가 하나일 때의 이야기다. 저장소가 늘어나면 — 특히 다른 저장소의 개념을 분석해 내 저장소에 영입해야 할 때마다 — 매번 두 저장소를 동시에 풀-스캔하는 비용이 기하급수적으로 늘어난다.
1.2 Grep ALL의 컨텍스트 폭발
문제의 본질은 검색 도구가 가진 정보의 단위에 있다. grep/rg는 라인 단위로 매치를 돌려준다. AI 에이전트는 그 라인의 의미를 파악하기 위해 주변 컨텍스트를 추가로 요구한다. "주변 50줄을 더 보여줘", "이 메서드의 호출자를 모두 찾아줘", "이 클래스가 어떤 모듈에 의존하는지 보여줘". 매 질문마다 새로운 grep, 새로운 50줄 컨텍스트, 새로운 토큰 비용.
저장소 둘을 비교 분석하라고 하면 같은 사이클이 두 배가 된다. 토큰 비용은 두 배가 아니라 곱해진다 — 한 저장소의 컨텍스트가 다른 저장소의 검색을 트리거하기 때문이다.
CodeScan은 이 비용 곡선을 평탄하게 만들기 위한 도구다. 한 번 인덱싱한 뒤에는 에이전트가 묻는 모든 질문이 SQLite 한 번의 쿼리로 끝난다. 라인이 아니라 구조 — 클래스, 메서드, 작성자, 의존성 관계 — 가 단위가 된다.
2. CodeScan이 선택한 세 가지 길
2.1 대 CLI 시대 — MCP가 아니라 스킬 + CLI

2025년이 MCP(Model Context Protocol)의 해였다면, 2026년은 CLI(Command-Line Interface, 명령줄 인터페이스)의 귀환이다. 두 패러다임은 배타적이지 않지만, 적절한 자리는 분명히 다르다.
- MCP가 빛나는 곳 — 원격 서비스, 권한이 필요한 API, 상태를 가진 외부 시스템. 한 번 연결되면 세션 내내 살아 있는 채널이 필요한 경우.
- CLI가 빛나는 곳 — 로컬 파일시스템 탐색, 즉시 끝나는 단발 호출, 결정적인 출력. 특히 로컬 저장소 분석처럼 매번 같은 컴퓨터에서 같은 디렉터리를 보는 작업.
MCP는 강력하지만 비용이 있다. 클로드 코드가 시작하자마자 등록된 MCP 서버 목록을 모두 로드한다 — 각 서버의 도구 스키마와 설명이 컨텍스트 윈도우에 자리를 차지한다. MCP 서버 10개를 등록한 세션은 첫 메시지를 보내기 전부터 수천 토큰을 이미 잃은 상태로 시작한다. 서버 한 개가 평균 5-10개의 도구를 노출하고, 각 도구가 수백 토큰 분량의 스키마/설명을 가진다고 잡으면 그게 곧 5,000-10,000 토큰이다.
CLI는 다르다. 클로드 코드의 Skill 2.0은 단순한 프롬프트 모음이 아니라 CLI 스크립트를 이해하고 호출할 줄 아는 작은 앱이다. 스킬은 트리거가 매칭될 때만 로드되고, 호출이 끝나면 사라진다. 컨텍스트 비용은 호출 직전·직후에만 발생한다.
스킬 1.0이 프롬프트의 모임이었다면, 스킬 2.0은 작은 AI 앱이다. CLI 생태계의 폭발적 성장과 스킬 2.0의 성장은 같은 곡선을 그린다.
CodeScan은 처음부터 스킬 + CLI 조합을 전제로 설계되었다. 따라서 MCP 서버 형태로 상주하지 않는다. 사용자(혹은 그 사용자가 위임한 AI 에이전트)가 필요할 때 codescan search, codescan query, codescan graph 같은 한 줄 명령으로 호출하고, 결과를 받으면 프로세스는 즉시 종료된다.
2.2 라이트웨이 — SQLite + FTS5 trigram
분석 결과를 어디에 저장할 것인가. Elasticsearch도, 별도 서버 프로세스도, 외부 DB 서비스도 아니다. 임베디드 SQLite 파일 하나 — ~/.codescan/db/codescan.db. 이 결정 하나로 따라오는 결과가 많다.
- 추가 데몬 프로세스 없음 — 사용자가 의식할 시스템 자원이 없다
- 백업/이주가 파일 복사 한 번 — 다른 노트북으로 갈 때
.codescan/폴더만 가져가면 동일한 상태 - 의존성이 SQLite 한 줄로 끝남 — 도구 자체가 깨지지 않는다
여기서 핵심 기술은 SQLite의 FTS5 가상 테이블이다. FTS5(Full-Text Search 5)는 SQLite 3.9 이후 표준에 포함된 풀텍스트 검색 확장으로, 인덱싱된 텍스트에 대해 키워드 검색을 밀리초 단위로 돌려준다. 그러나 기본 토크나이저는 공백 기준 단어 분리 — 한국어·일본어·중국어처럼 띄어쓰기가 약하거나 단어 경계가 흐릿한 언어에서는 잘 동작하지 않는다.
CodeScan은 trigram 토크나이저를 채택한다. trigram은 텍스트를 연속된 3글자 조각으로 쪼개 색인하는 방식이다 — "HttpClient"는 Htt, ttp, tpC, pCl, ... 의 시퀀스가 되고, 한국어 "사용자관리"는 사용자, 용자관, 자관리 가 된다. 결과적으로:
- 부분 문자열 검색이 자연스럽게 동작한다 —
Client만 입력해도HttpClient/MyClient/ClientFactory가 모두 매치 - CJK(한·중·일) 검색이 동등하게 빠르다 — 별도의 형태소 분석기 없이 trigram으로 동작
- 메서드명 부분 검색 — 카멜케이스든 스네이크케이스든 똑같이 잡힌다
Services/SqliteStore.cs:151에 이 의도가 그대로 적혀 있다:
// FTS5 for full-text search (trigram tokenizer for Korean substring matching)
CREATE VIRTUAL TABLE IF NOT EXISTS search_index USING fts5(
...
tokenize='trigram'
);
trigram이 사용 불가한 환경(구버전 SQLite 빌드)에서는 기본 토크나이저로 자동 폴백한다. AI 에이전트는 이 차이를 알 필요가 없다 — 동일한 codescan search 명령이 환경에 따라 가장 좋은 길로 알아서 흐른다.
2.3 그래프 DB — 코드도 별자리가 될 수 있다
최근 2~3년 사이 Wiki·옵시디언·Roam Research 같은 지식 관리 도구들이 **그래프 RAG(Retrieval-Augmented Generation, 검색 증강 생성)**의 유행을 한 번 탔다. 노트끼리의 양방향 링크가 자동으로 그래프를 만들고, 그 그래프 위를 탐색하면 "관련 문서"가 떠오른다. 핵심은 개별 노트의 내용이 아니라 노트끼리의 관계가 정보를 만든다는 점이다.
코드도 정확히 같은 구조다. 함수 하나는 다른 함수를 호출하고, 클래스는 다른 타입을 사용하고, 파일은 모듈을 임포트한다. 코드도 로컬에서 관리되는 문서이며, 따라서 그래프가 가능하다.
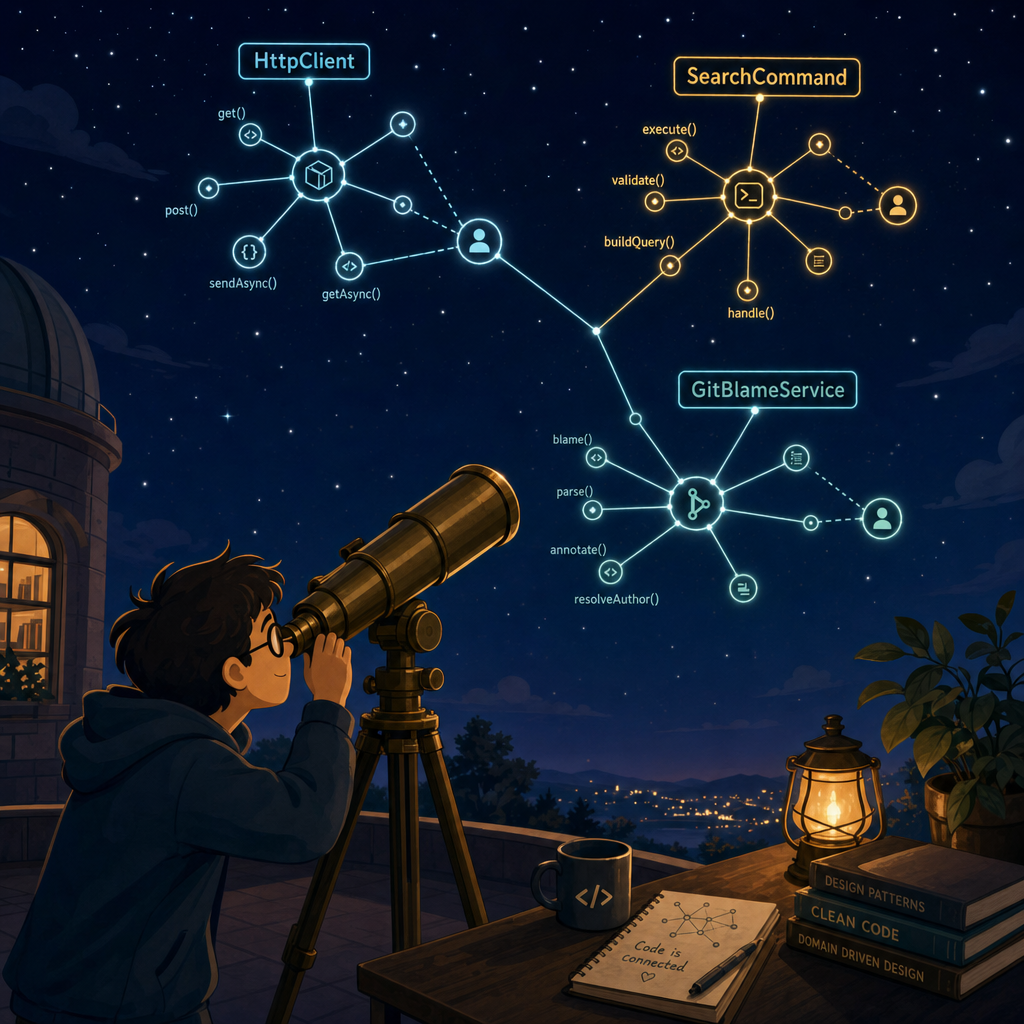
CodeScan은 분석 결과를 두 개의 테이블에 그래프 형태로 저장한다:
| 테이블 | 내용 |
|---|---|
graph_nodes | project, directory, file, class, method, comment, doc, author, type, module |
graph_edges | contains, defines, authored, has_comment, documents, imports, inherits_or_implements, creates, uses_type |
이 두 테이블만 있어도 다음과 같은 질문이 한 줄 쿼리로 답해진다:
- "
HttpClient를 사용하는 클래스 모두 찾기" —uses_type엣지를 따라간다 - "
SearchCommand의 작성자 누구?" —authored엣지의 source 노드 - "
System.Net.*을 임포트하는 파일 모두 찾기" —imports엣지 + 모듈 이름 필터 - "이 클래스가 상속하는 타입의 생성자 호출 추적" —
inherits_or_implements+creates두 단계 탐색
별자리는 키워드 매치보다 한 단계 위의 정보다. 키워드는 "이 단어가 어디 나왔어?"에 답하지만, 그래프는 "이 개념이 코드베이스에서 어떻게 살아 움직이는가?"에 답한다.
2.3.1 Cypher-like 질의 — AI가 SQL을 모르게
그래프 데이터가 SQLite에 있다고 해서, AI 에이전트가 매번 SQL JOIN을 짜야 한다면 사용성이 망가진다. CodeScan은 Cypher-like 질의 서브셋을 자체 파서로 제공한다. Cypher는 Neo4j 그래프 DB의 질의 언어로, 그래프 패턴을 가장 자연스럽게 표현한다.
# 클래스 노드 중 'Service' 가 포함된 것
codescan query "MATCH (c:class) WHERE c.label CONTAINS 'Service' LIMIT 20"
# HttpClient 를 사용하는 클래스
codescan query "MATCH (c:class)-[r:uses_type]->(t:type) WHERE t.label = 'HttpClient'"
# System.Net.* 을 임포트하는 파일
codescan query "MATCH (f:file)-[r:imports]->(m:module) WHERE m.label CONTAINS 'System.Net'"
# 작성자 'kim' 의 메서드 + 이웃 한 단계 확장
codescan query "MATCH (a:author)-[r:authored]->(m:method) WHERE a.label CONTAINS 'kim'" --depth 1
이것은 풀 Cypher가 아니다. CodeScan의 SQLite 스키마에 매핑되는 안전한 부분집합 — MATCH ... WHERE ... LIMIT ... — 만 지원한다. 임의 SQL 인젝션 표면을 막으면서, 에이전트가 외울 만한 표현력은 충분히 확보했다.
지원 연산자도 단순하다: =, CONTAINS, STARTS WITH, ENDS WITH. 그리고 AND 로 조건을 묶는다. 그래프 데이터를 처음 만지는 에이전트도 README 한 페이지만 보면 쓸 수 있는 수준으로 의도적으로 좁혔다.
2.3.2 정규식 우선 + 의미 분석 프로브 — 빌드 없이도 작동한다
레거시 코드를 다룰 때 가장 자주 마주치는 벽은 빌드가 안 됨이다. 컴파일러 기반 분석(Roslyn, JDT, TypeScript Compiler API)은 정확하지만 빌드가 성공해야 시작한다. 의존성이 깨진 채로 받은 저장소에서는 한 발짝도 못 나간다.
CodeScan은 의도적으로 하이브리드 전략을 택한다:
| 단계 | 전략 | 의존성 |
|---|---|---|
| 1차 | 언어 중립적 정규식 추출 | 없음 — 파일만 읽으면 됨 |
| 2차 | 빌드 시스템 메타데이터 탐지 (.csproj, pom.xml, tsconfig.json, go.mod, Cargo.toml, compile_commands.json) | 현재는 감지만 — 향후 의미 분석 추가용 프로브 |
결과적으로 첫 스캔은 빌드 없이 즉시 끝난다. 정규식이 잡아낸 의존성 엣지는 100% 정밀하진 않지만, "이 클래스가 대략 어떤 것과 엮여 있는가"를 별자리로 그리기에는 충분하다. 빌드 가능한 저장소에서는 향후 의미 분석 프로브가 활성화되며 정확도가 올라간다.
이 설계는 다른 저장소의 개념을 영입하는 사용 시나리오와 직접적으로 맞물린다. 영입 후보로 잡은 오픈소스가 빌드 환경 세팅이 까다로워도, CodeScan은 일단 별자리를 그려준다. 영입 결정을 내릴 만큼의 구조 파악은 가능해진다.
2.3.3 실제 사례 — AgentZero가 자신의 아키텍처를 설명하다
이 별자리가 AI 에이전트의 손에 쥐어졌을 때 어떤 일이 벌어지는가. 자매 프로젝트 AgentZeroLite에서 실제 테스트를 진행했다. 미션 정의와 수행 결과가 모두 공개되어 있다:
- 미션 정의: M0023 — 아키텍처 문서 업데이트
- 수행 결과: M0023 — 수행결과
요약하면 — 에이전트에게 "이 저장소의 아키텍처 문서를 작성하라"는 미션을 주고, 도구로 CodeScan을 쥐어 줬다. 에이전트는 다음 순서로 움직였다:
codescan projects로 인덱싱된 저장소 목록 확인codescan graph로 최상위 노드들의 위계 파악codescan query "MATCH (c:class)-[r:contains]->(m:method)"로 클래스-메서드 트리 수집codescan query "MATCH (a:author)-[r:authored]->(m:method)"로 모듈별 핵심 작성자 추출- 위 결과를 합쳐 단순 키워드 검색만으로는 도달할 수 없는 아키텍처급 설명을 생성
결정적인 차이는 5번이다. grep 결과만 받았다면 에이전트는 "이런 클래스가 있다", "이런 메서드가 있다"의 나열에 머무른다. 그래프를 받으면 "어떤 클래스가 시스템의 허브이고, 어떤 메서드가 변경 영향이 크고, 어떤 모듈이 외부 경계인가"의 설명이 가능해진다. (여기서 변경 영향(change impact) — 이 변경이 다른 코드를 얼마나 흔드는가.)
2.3.4 1차 시각화는 텍스트 메타 — 사람과 LLM이 같은 것을 본다
여기서 말하는 "시각화"는 사람만의 것이 아니다. LLM(Large Language Model, 거대 언어 모델)이 그대로 읽어 들이는 형태까지 포함한다.
그래프라고 하면 흔히 화려한 노드/엣지 시각화 도구를 떠올린다. CodeScan은 로컬 웹 GUI(codescan gui start)로 2D/3D 그래프 뷰어도 제공하지만, 더 본질적인 시각화는 다른 곳에 있다 — 텍스트 메타 정의 자체다.

위와 같은 텍스트 형태의 메타데이터(노드 종류, 엣지 종류, 관계 표)는 머메이드나 draw.io 이미지로도 표현할 수 있다. 그러나 텍스트 메타는 한 가지를 더 한다 — 그 자체가 LLM에게 코드를 설명해 주는 1차 입력이 된다. 이미지를 OCR(Optical Character Recognition, 광학 문자 인식)로 다시 해석할 필요가 없다. 그래프의 형태와 의미가 같은 텍스트에 담겨 있다.
이미지는 사람을 위한 것이고, 텍스트 메타는 사람과 에이전트 모두를 위한 것이다.
3. 배포 전략 — Native AOT 단일 바이너리

블룸AI의 개발팀은 윈도우, WSL 리눅스, 맥을 골고루 쓴다. 이 다양성을 한 번의 빌드로 끝내는 길이 .NET 10 Native AOT(Ahead-of-Time) 단일 바이너리다.
| OS | 아키텍처 | 한 줄 설치 |
|---|---|---|
| Windows | x64 | winget install psmon.CodeScan |
| macOS | arm64 (Apple Silicon) | brew install psmon/codescan/codescan |
| Linux | x64 / arm64 | npm install -g @webnori/codescan-cli |
설치 후 ~/.codescan/bin/codescan 한 파일만 있으면 .NET이 설치되지 않은 머신에서도 그대로 실행된다. 런타임 의존성이 없고, JIT(Just-In-Time) 컴파일러 워밍업이 없고, 메모리 풋프린트가 작다.
이 형태가 단지 "편하다" 수준의 가치가 아닌 이유는 — 엣지 AI(edge AI — 클라우드 서버가 아니라 사용자에게 가까운 단말·장치에서 직접 추론을 수행하는 형태)라는 흐름과 정확히 맞물리기 때문이다.
3.1 왜 AOT인가 — 엣지·SBC에는 런타임이 없다
엣지와 SBC(Single Board Computer, 단일 보드 컴퓨터)에는 런타임이 없다 — 따라서 단일 AOT 바이너리는 사치가 아니라 전제 조건이다. 이 전제는 2026년 들어 갑자기 무거워졌다.
2025년까지의 "엣지 LLM" 이야기는 데모와 벤치마크 글에 머물러 있었다. 2026년부터 분위기가 달라졌다.
- 구글 Gemma 3 / 3n / 3 270M — Gemma 3는 라즈베리 파이에서 14.5 tok/s를 기록했고, 270M 변종은 INT4(4비트 정수) 양자화 + PLE 캐시로 Pixel 9 Pro에서 25회 대화에 배터리 0.75% 소모를 보여줬다. 일상 기기 탑재 수준에 진입했다는 신호다. (Gemma 3 270M 발표)
- 엔비디아 Nemotron 3 Nano (4B / 30B-A3B) — 하이브리드 MoE(Mixture of Experts, 전문가 혼합) 구조로 30B 중 forward pass당 3B만 활성화. 4B 변종은 4비트 양자화 시 VRAM 3 GB 미만으로 컨슈머 RTX와 Jetson급 보드에서 동작한다. (Nemotron 3 Nano Omni)
- 3B 파라미터가 SBC의 최적점 — 양자화 안정화와 소형 NPU(Neural Processing Unit, 신경망 처리 장치)의 보급으로, 커뮤니티가 약 3B를 SBC의 실용적 최적점으로 수렴시키고 있다.
이런 환경의 공통 제약은 단순하다 — 런타임이 없다. 드론 펌웨어, SBC 미니멀 이미지, 산업용 PLC 옆 박스 어디에도 .NET/Java/Python 런타임은 사전 설치되어 있지 않다. 단일 self-contained 바이너리는 선택지가 아니라 요구사항에 가깝다.
CodeScan은 직접 LLM(Large Language Model, 거대 언어 모델)을 호스트하지 않는다. 대신 SLM(Small Language Model, 소형 언어 모델)이 코드와 상호작용할 때 필요한 인덱싱·검색 레이어를 맡는다:
- SBC에서 도는 코드 인지형 에이전트(예: Gemma 3 4B + tool-use)가 로컬 저장소를 빠르게 훑는 FTS5 + 그래프 백엔드
- 자율 빌드/배포 봇이 변경 영향 범위를 추론하는 Cypher-like 그래프 질의 표면
- 드론·로봇 SDK(Software Development Kit) 저장소를 오프라인 분석하여 SLM에 코드 컨텍스트를 주입하는 RAG-lite 컴포넌트
3.2 작은 모델 탑재는 열어 둔다
CodeScan v1의 두뇌는 외부 — 즉 클로드 코드, 코덱스, 또는 사용자가 선택한 다른 에이전트 — 다. 분석 자체는 결정적인 규칙(정규식·SQL·그래프 질의)이므로 LLM이 필요 없다. 도구는 도구에 머문다.
그러나 설계상의 문은 열려 있다. 향후 코드 분석 품질에 도움이 되는 스몰 모델이 등장하면 — 예컨대 함수 요약, 변수명 의도 추론, 코드 스멜 분류에 특화된 1~3B 모델이 안정화되면 — codescan 바이너리에 직접 탑재해 분석 파이프라인의 한 단계로 끼울 수 있다. AOT 단일 바이너리는 이런 작은 LLM의 동봉과 자연스럽게 어울린다.
이는 약속이 아니라 남겨둔 선택지다. 블룸AI 팀은 클로드와 코덱스를 적극 채택해 활용하므로, 굳이 자체 추론을 끼울 동기가 지금은 약하다. 외부 모델이 충분히 좋다면 도구는 도구로 남는 편이 낫다.
4. 어디에 쓰는가 — 그리고 어디엔 쓰지 않는가
4.1 작은 코드베이스에는 과한 도구다
먼저 솔직하게 — 코드량이 많지 않다면 CodeScan은 필요 없다. 요즘 클로드 코드를 포함한 주요 에이전트들은 충분한 컨텍스트 윈도우를 제공하고, 단일 저장소의 풀-grep은 여전히 가장 직관적이고 빠른 시작점이다. 도구를 인덱싱해서 쓰는 것보다 그대로 읽는 편이 빠르다.
4.2 CodeScan이 빛나는 시나리오
세 가지가 겹칠 때 가치가 분명해진다:
- 저장소 수가 많다 — 한 사람의 워킹 디렉터리에 관리 대상 저장소가 5개 이상
- 저장소 사이의 관계가 중요하다 — A 저장소가 B 저장소의 개념을 이해하거나 영입해야 함
- 에이전트와 함께 작업한다 — 사람이 직접 모든 파일을 열어 읽지 않고, AI에게 컨텍스트를 쥐어 주는 형태
이 셋이 겹치는 가장 흔한 구체적 상황:
- 레거시 마이그레이션 — 낡은 저장소의 구조를 새 저장소로 옮기기 전, 의존성 별자리를 먼저 그려본다
- 오픈소스 영입 검토 — 영입 후보 저장소가 빌드 안 되는 상태여도 정규식 기반 그래프로 1차 평가
- 다중 저장소 디버깅 — 마이크로서비스 또는 분리된 모노레포에서 한 변경이 어디에 영향을 미치는지 탐색
- 아키텍처 문서화 — 위의 AgentZero 사례처럼, AI에게 "이 저장소를 아키텍처급으로 설명하라"는 미션을 줄 때
핵심은 한 줄로 요약된다:
내 폴더의 코드 저장소를 모두 스캔해 둔다. 그 다음부터 에이전트에게는 "관련 코드는 CodeScan에 인덱싱되어 있으니 거기서 찾아라"고 알린다. 세션마다의 컨텍스트 누적이 거기서 멈춘다.
5. 마치며 — 설명할 수 없는 코드, 설명할 수 있는 도구

사람이 100% 직접 짠 코드는 그 작성자가 설명할 수 있다. 그러나 우리는 점점 더 많은 코드를 승인하고 생성을 의뢰한다. 모든 라인을 다 본 적이 없는 코드가 우리의 저장소를 채워간다.
여기에 두 가지 본질적 한계가 있다:
- LLM은 스스로를 설명하지 못한다 — 자신이 왜 그런 출력을 냈는지 알지 못한다
- 그러나 하네스 엔지니어링은 스스로를 설명하고 개선할 수 있다 — 로그를 남기고, 평가 기준을 갖고, 다음 사이클에서 더 나아진다
CodeScan은 이 두 번째 흐름의 작은 장치 한 조각이다. 모델을 직접 개선하지는 않지만, 모델이 코드와 상호작용할 때 무엇을 보고 있는지를 명시적인 별자리로 만들어 준다. 별자리는 텍스트로도 표현되고, 그래프로도 표현되며, 두 표현은 동일한 의미를 갖는다 — 따라서 모델 교체에도 살아남는다.
코드는 점점 설명하기 어려워지지만, 코드를 보는 도구는 설명 가능해야 한다. CodeScan은 그 작은 약속이다.
이 작은 도구를 BlumnAI-Studio/CodeScan에 공개한다. 라즈베리 파이부터 맥북까지, 윈도우 노트북부터 리눅스 서버까지 — 같은 한 파일이 그대로 동작한다. 별자리를 그려 보고 싶은 저장소가 하나라도 있다면, 시작은 한 줄이다:
codescan scan
참고
- CodeScan:
- BlumnAI-Studio/CodeScan (GitHub)
- README — 한국어 — 전체 기능·CLI 명령·그래프 스키마
- 자매 프로젝트 — AgentZeroLite:
- BlumnAI-Studio/AgentZeroLite — 온디바이스 SLM 호스팅과 에이전트 루프
- M0023 — 아키텍처 문서 업데이트 미션 정의
- M0023 — 수행 결과 로그
- 기반 기술:
- SQLite FTS5 공식 문서 — trigram 토크나이저 섹션
- .NET Native AOT 배포 — Microsoft Learn
- 엣지 AI / 온디바이스 SLM:
- 블룸AI 스튜디오:
- blumn.ai — 차세대 AI 에이전트 / 실시간 엣지 AI 인프라 R&D Studio